
1 はじめに
Unicodeについて、自分なりに整理してみました。
最近(2010年以降)で扱う文字のコードはほとんどがUTF-8となってしまいましたが、
今までじっくりその構造をみたことがありません。
昔バイナリーダンプを見たことがありましたが、その当時は見てもさっぱりワケわからん!
ということで、少し余裕ができましたので、調べてみました。
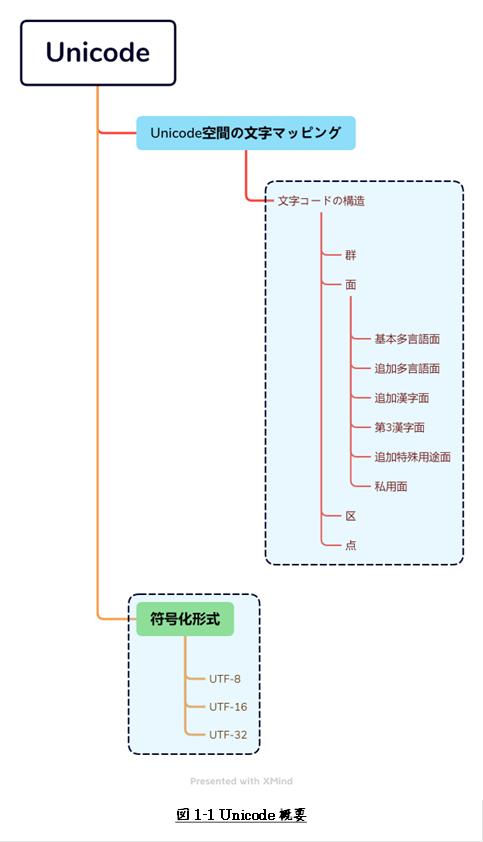
本記事は、なるべくわかりやすく読まれるよう図1-1に
示すよう構成してみましたが、
どうでしょうか。
まず、Unicode空間において文字がどのようにマッピングされているか、が理解の出発点です。
マッピングされた文字の数値は、コードポイント(符号位置)と言われるようです。
そのコードポイントがどのように符号化されているかで、
いわゆるUTF-8、UTF-16、UTF-32が理解できるのではないかと思います。
# 翻訳文は、わたし個人としてはどうも読みにくい。
# 物事のとらえ方のステップが日本語とは違うらしいので、
# 日本語になったからといって分りにくいことに変わりはない。
2 Unicode文字集合
2.1 Unicode文字の構造
符号化されていないUnicodeの文字コードは、UCS-4(UCSは、ISO/IEC 10646の略)、
またはUTF-32と呼ばれています。
Unicodeの完全な拡張機能を定義することができ、
最大で1,000,000を超える固有の文字を定義できます。
UCS-4では、文字は4オクテット(4バイト)で表され、上位から
・ 群オクテット
・ 面オクテット
・ 区オクテット
・ 点オクテット
と呼ばれます。

群オクテットで群を、面オクテットでは面を、区オクテットで区を、点オクテットで点を指定し、
各点に符号化文字がマッピングされます。
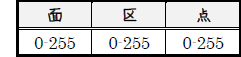
符号空間は第0-127の128群に、各群は第0-255の256面に、各面は第0-255の256区に、
各区は第0-255の256点に分かれます。
Unicodeでは、これらのうち、第0群第0-16面のみを使うことができます。
Unicodeの符号空間を分割する最初の単位は、群ではなく面です。
2.2 面
現在のUnicodeで実際に使っているのは、Unicode 5.1からのようで、
表2.2-1に示す6面です。
第1面以降は、追加面と呼ばれています。
ちなみに、2023年10月での最新バージョンは、15.0.0となっています (Unicode 歴史参照)。

- 基本多言語面(BMP)
-
UCS-4およびUnicodeの最初の面であり、
最初の65536の符号位置 000016-FFFF16からなります。
基本他言語面には、通常使われる文字のほとんどが収録されています。
- 追加多言語面(SMP)
-
現在使うもののいない古代の用字系や人工文字など、
基本多言語面に入りきらなかった文字のうち漢字以外が収録されています。
- 追加漢字面(SIP)
- 追加漢字面(SIP)には、基本他言語面に入りきらなかった漢字が収録されています。
- 第三漢字面(TIP)
- 第三漢字面(TIP)には、追加漢字面に入りきらなかった漢字および古代の漢字が収録されています。
- 追加特殊用途面(SSP)
- 追加特殊用途面((SSP)には、書式制御文字が収録されています。
- 私用面
-
第15-16面が(BMPのE00016-F8FF16に加え)、
当事者間の私的な合意によって文字を定義できる私用領域を私用面とされています。
ISO/IEC 10646(略称: UCS)では
さらに第0群第224-255面と第96-127群が私用領域とされていましたが、
2002年の改訂で削除され、Unicodeと同等になりました。
- 予約された面
-
ISO/IEC 10646では、
第0群第17-223面と第1-95群は将来の標準化のために予約されていました。
2006年の改訂で、Unicodeで使用できない第0群第17面以降と第1群以降は
全て永久に予約された面および群となり、文字が定義されないことになりました。
2.3 基本多言語面(BMP)
2.3.2 符号化
基本他言語面の符号位置は、
UTF-8やUTF-16では、他の面より少ないオクテット(バイト)数で符号化されます。
・ UTF-8では、1~3オクテットで符号化される。
・ UTF-16では、2オクテットで符号化される。
サロゲートペア(代用対)は必要がないため使われない。
・ UTF-32では、他の面と同様4オクテットで符号化される。
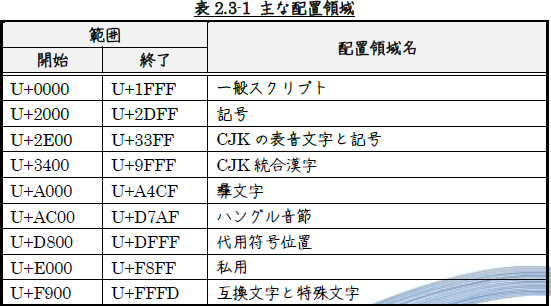
2.3.3 配置領域
基本多言語面は、同種の用字をまとめた、いくつかの配置領域に分かれています。
2.3.4 Unicodeコード一覧の見本
CJK統合漢字コード表の一部を下に示します。
CJK統合漢字(シージェーケーとうごうかんじ、英: CJK unified ideographs)は、
ISO/IEC 10646およびUnicodeにて採用されている符号化用漢字集合およびその符号表です。
CJK統合漢字の名称は、
中国語(英: Chinese)、日本語(英: Japanese)、朝鮮語(英: Korean)で
使われている漢字をひとまとめにしたことからきています。

2.4 追加多言語面(SMP)
2.4.1 概説
現在使うもののいない古代の用字系や人工文字など、
基本多言語面に入りきらなかった文字のうち漢字以外を収録します。
追加多言語面には、以下のようなスクリプトが収録されています。
・ 希に使われる歴史的スクリプト: 線文字B、ゴート文字など
・ 特殊用途の創作スクリプト: デザレット文字、シェイヴィアン文字など
・ 特殊な表記システム: 音楽記号など。
- 【参照元】
- 追加多言語面
2.4.2 符号化
追加多言語面の文字は、2オクテット固定長方式のUCS-2では使用することが出来ず、
UTF-8、UTF-16、UTF-32のいずれの符号化方式でも4オクテットで符号化されます。
UTF-16ではサロゲートペア(代用対)を使う必要があります。
2.4.3 配置領域
表2.4-1に、日本語に関係すると思われる追加他言語面の領域を示します。

2.5 追加漢字面(SIP)
2.5.2 符号化
追加漢字面の文字は、2オクテット固定長方式のUCS-2では使用することが出来ず、
UTF-8、UTF-16、UTF-32のいずれの符号化方式でも4オクテットで符号化されます。
UTF-16ではサロゲートペア(代用対)を使う必要があります。
2.6 第三漢字面(TIP)
2.6.1 概説
ロードマップにおいては甲骨文字・金文・小篆といった現在一般的には使用されない
古代の漢字を将来的に収録する予定の追加面の一つでありましたが、
後述の通り、追加漢字面に入りきらなかった(現代の書体に基づく)漢字が最初に収録されました。
- 【参照元】
- 第三漢字面
2.6.2 符号化
第三漢字面の文字は、2オクテット固定長方式のUCS-2では使用することが出来ず、
UTF-8、UTF-16、UTF-32のいずれの符号化方式でも4オクテットで符号化されます。
UTF-16ではサロゲートペア(代用対)を使う必要があります。
2.7 追加特殊用途面(SSP)
2.7.1 概説
追加特殊用途面には、言語タグや異体字セレクタなどの制御コードが収録されています。
言語タグは、テキストにそれが何語かという言語情報を付けるものです。
異体字セレクタは、文字の字形をより詳細に指定するものであり、基本多言語面にもありますが、
IVSではこの追加特殊用途面にあるものを使います。
IVSについては、こちらのページを参照してください。
VD/IVSとは / 文字情報技術促進協議会
- 【参照元】
- 追加特殊用途面
2.7.2 符号化
追加特殊用途面は、2オクテット固定長方式のUCS-2では使用することが出来ず、
UTF-8、UTF-16、UTF-32のいずれの符号化方式でも4オクテットで符号化されます。
UTF-16ではサロゲートペア(代用対)を使う必要があります。
2.8 私用面
2.8.1 概説
Unicodeでは、基本他言語のE00016-F8FF16に加え、
第15-16面が
当事者間の私的な合意によって文字(外字)を定義できる私用領域
とされています。
このうち、私用領域だけに使われる面(すなわち、第15面と第16面)を私用面といいます。
規格としては、この範囲にいかなる文字も規定していません。
私用領域の内容を定義するものとしては、
ISOやユニコードコンソーシアム以外の個人、組織およびソフトウェアベンダが想定されています。
- 【参照元】
- 私用面
2.8.2 符号化
私用面は、2オクテット固定長方式のUCS-2では使用することが出来ず、
UTF-8、UTF-16、UTF-32のいずれの符号化方式でも4オクテットで符号化されます。
UTF-16ではサロゲートペア(代用対)を使う必要があります。
3 符号化形式
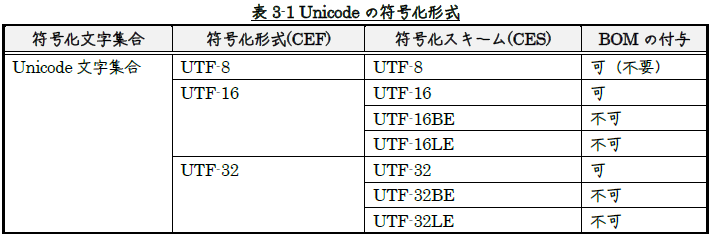
Unicodeでは文字符号化形式として、UTF-8、UTF-16、UTF-32の3種類が定められています。
3.1 UTF-8(8-bit UCS Transformation Format)
UTF-8は1符号化文字を1~4符号単位で表す可変幅文字符号化形式で、
1符号単位は8ビット(1オクテット)です。
ASCII文字と互換性を持たせるために、ASCIIと同じ部分は1バイト、
その他の部分を2~6バイトで符号化します。
4オクテットのシーケンスでは21ビット(0x1FFFFF)まで表現することができますが、
Unicodeの範囲外となる17面以降を表すもの(U+10FFFFより大きなもの)は受け付けません。
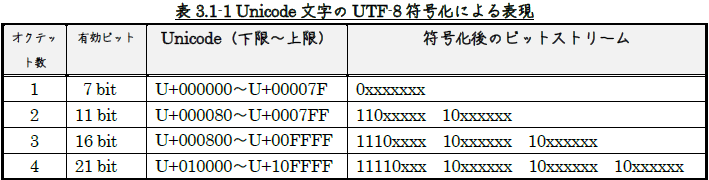
表3.1-1において、
「x」は元の文字コード中のbitデータをそのまま埋め込むことを表します。
UTF-8では文字コードに応じて符号化後の長さが変わり、
よく使われる文字ほど短いデータになります。
基本他言語面(U+0000~U+FFFF)以外のUnicode文字は4バイトに変換されます。
【UTF-8による符号化の特徴】
最も頻繁に使われるU+0000~U+007Fの文字(ASCII文字/半角英数字)は
1バイトに収まるようにして、コード効率を高くしています。
アルファベット圏でよく使われる文字範囲(U+0080~U+07FF)は2バイトで済むので、
やはりコード効率がよい。
基本的な漢字文字はほぼ基本他言語面(U+0000~U+FFFF)に収容されているため、
ほとんどの日本語文字は3バイトになる。
符号化後のバイトデータの上位bitのパターンを見ると、
どこがUnicode文字の先頭かすぐに分かります
(上位bitが00か01か11なら文字の先頭バイト、10なら非先頭バイト)。
3.2 UTF-16 (16-bit UCS Transformation Format)
UTF-16は1符号化文字を1~2符号単位で表す可変幅文字符号化形式で、
1符号単位は16ビットです。
基本多言語面の文字を符号単位一つで、
その他の文字をサロゲートペア(代用対)という仕組みを使い符号単位二つで表現します。

【サロゲートペア(代用対)】
表3.2-1の2行目は、 サロゲートペアによる符号化を示したものです。
サロゲートはUnicodeの符号位置のU+010000~U+10FFFFの範囲を
16ビットユニットのペア(2つ)で表現する集合で、
最初の16ビットユニットを前半サロゲートもしくはハイサロゲート、
二番目を後半サロゲートもしくはローサロゲートと称します。
ハイサロゲートはU+D800~U+DBFFの範囲、 ローサロゲートはU+DC00~U+DFFFの範囲です。
【BOM】
BOMは、通信やファイルの読み書き等、8ビット単位の処理でオクテット順を識別するための印で、
データストリームの先頭に付与されます。
値はU+FEFF。
システムが読み込んだ先頭2オクテットがFF FEならリトルエンディアン、
FE FFならビッグエンディアンとして後に続く文書を処理します。
3.3 UTF-32(32-bit UCS Transformation Format)
UTF-32は1符号化文字を1符号単位で表す固定幅文字符号化形式で、
1符号単位は32ビットです。
ただし、Unicodeの符号空間がU+10FFFFまでであるため、
実際に使われるのは21ビットまでです。
UTF-32符号化方式でもUTF-16符号化方式と同じく、
ビッグエンディアンとリトルエンディアンが存在し、
それぞれUTF-32BE、UTF-32LEと呼ばれます。
テキスト形式で扱う場合、UTF-32は先頭にオクテット順マーク(BOM)をつけます。
先頭の4オクテットの並びがFF FE 00 00ならリトルエンディアンとなり、
00 00 FE FFならビッグエンディアンとなります。
プロトコルもしくはアプリケーションの設定などの手段で符号化方式に
UTF-32BEやUTF-32LEを指定している場合には、BOMを付与することは許容されません。
4 参考資料
本記事は、以下の資料を参考にした。
・
Unicode
・
面 (文字コード)
・
基本多言語面
・
追加多言語面
・
追加漢字面
・
第三漢字面
・
追加特殊用途面
・
私用面
・
UTF-8
・
UTF-16
・
UTF-32
・
Unicode一覧表
以上
HTMLだと、
思うように編集することは難しく、やろうすればとっても時間が掛かります。
ですので、本記事の元となっているWordで作成したPDFを
ページ最後に貼り付けました。
少しでも役に立てていただければ、うれしく思います。
このPDFファイルは、自由に配布されてもかまいません。
ただし、再配布の際には、
入手元と著者名は明らかにしてください。
なお、上のPDFファイルの内容、また本文中の記述に、
誤字や脱字、誤った内容の記述など見つかりましたら、
下に示すフォームでご連絡いただければ幸いです。
コメント