変更履歴
- Rev. 0.7 : 2025年12月22日
- 新規作成
1 robots.txtとは?
Google Search Consoleの機能を調べていたら、“robots.txt”という言葉に遭遇しましたので、
その役割をまとめてみました。
robots.txtは、必ずしも設置しなければならないものではないですが、
迷惑アクセスを繰り返す訪問者にサイト情報を知られ難くするなどの
対策の一つ として利用できそうです。
1.1 robots.txt
robots.txtは、Webサイトのルートディレクトリに置かれるテキストファイルで、
検索エンジンのクローラー(ロボット)に対して、
どのページやディレクトリをクロール(巡回)して良いか、
またクロールしてはいけないかを指示するためのものです。
1.2 robots.txtの役割と重要性
robots.txtは、Webサイトのクロール制御において重要な役割を果たします。
主な役割を下に示します。
- 1. クロール制御
-
特定のディレクトリやファイルを検索エンジンのクローラーからブロックし、
クロールさせないように指示します。 - 2. サーバー負荷軽減
-
不要なクロールを制限することで、サーバーへの負荷を軽減し、
Webサイトのパフォーマンスを向上させます。 - 3. 機密情報保護
-
管理ページや個人情報など、
検索結果に表示させたくない情報をクローラーから保護します。 - 4. 重複コンテンツ回避
- 重複コンテンツのクロールを制限し、検索エンジンの評価を最適化します。
1.3 robots.txtを設置すべきか
robots.txtは、必ずしも設置しなければならないものではありません。
下に示すような小規模サイトには、設置する必要はありません
(本記事は、小規模サイトをターゲットに記述しています)。
・ クロールを拒否したいコンテンツが特に無い
・ よほどページ数が多いサイトではない、また更新頻度が高くない
ただし、次のような場合は、設置した方がよいのかもしれません。
・ メディアファイル(画像・動画・音声ファイル)をGoogle検索結果に表示させたくない
・ Google Search Consoleで、
合計URLの大部分が「検出- インデックス未登録」に分類されてしまう
2 robots.txtの構文
2.1 robots.txtの基本的な構文
robots.txtは、シンプルなテキストファイルであり、
いくつかの基本的なディレクティブ(Directive)で構成されています。
2.1.1 robots.txt基本的なディレクティブ(Directive)
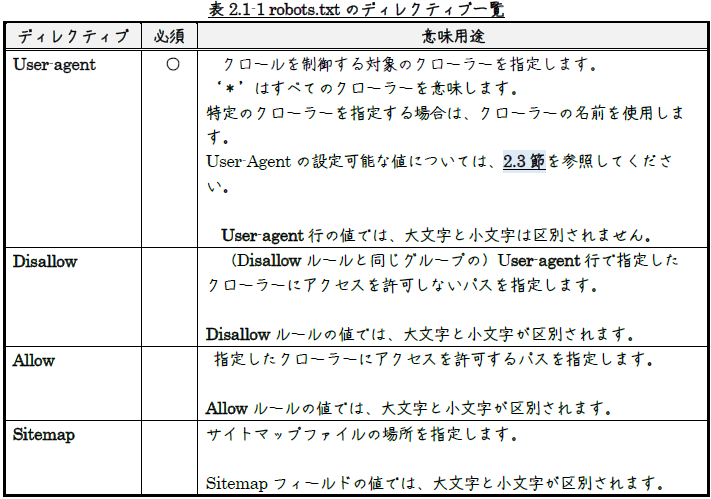
robots.txtには、表2.1-1に 示すようなディレクティブがあります。
詳しくは、次のページをご覧いただければと思います。
Google による robots.txt の指定の解釈 | Crawling infrastructure(developers.google.com)
robots.txtの有効な行は、フィールド、コロン、値で構成されます。
スペースは省略可能です。 ただし、読みやすくするために使用することが推奨されます。
行の先頭と末尾にある空白文字は無視されます。
一般的な形式は、次のようです。
|
1 |
<field>:<value><#optional-comment> |
2.1.2 行とルールのグループ化
複数のユーザー エージェントに適用するルールは、
各クローラーのUser-agent行を繰り返すことでグループ化できます。
|
1 2 3 4 5 6 7 8 9 10 11 |
user-agent: a disallow: /c user-agent: b disallow: /d user-agent: e user-agent: f disallow: /g user-agent: h |
2.1.3 記述例
|
1 2 3 4 5 6 |
User-agent: * Disallow: /admin/ Disallow: /tmp/ Allow: /public/ Sitemap: https://example.com/sitemap.xml |
この例では、すべてのクローラーに対して、
“/admin/”ディレクトリと“/tmp/”ディレクトリのクロールを禁止し、
“/public/”ディレクトリのクロールを許可しています。
また、サイトマップファイルの場所を、
“https://example.com/sitemap.xml”として指定して います。
2.2 robots.txtファイルの記述ルール
robots.txtファイルは、UTF-8エンコードされた書式なしテキストファイルでなければならず、
行の区切りにはCR、CR/LF、LFのいずれかを使用する必要があります。
robots.txtを記述する際には、以下のルールに従う必要があります。
- ファイル名
- ファイル名は、必ずrobots.txtである必要があります。
- 配置場所
-
Webサイトのルートディレクトリに配置する必要があります。
(例:“https://example.com/robots.txt”) - 大文字小文字
-
ファイル名は、大文字小文字を区別します。
通常は小文字で記述します。 - コメント
-
#記号を使ってコメントを記述できます。
コメントはクローラーによって無視されます。 - 複数指定
- User-agentごとに異なるルールを記述できます。
- 優先順位
-
AllowとDisallowが競合する場合、より具体的なルールが優先されます。
ルールの優先順位 | Crawling infrastructure(developers.google.com)
2.3 User-agent
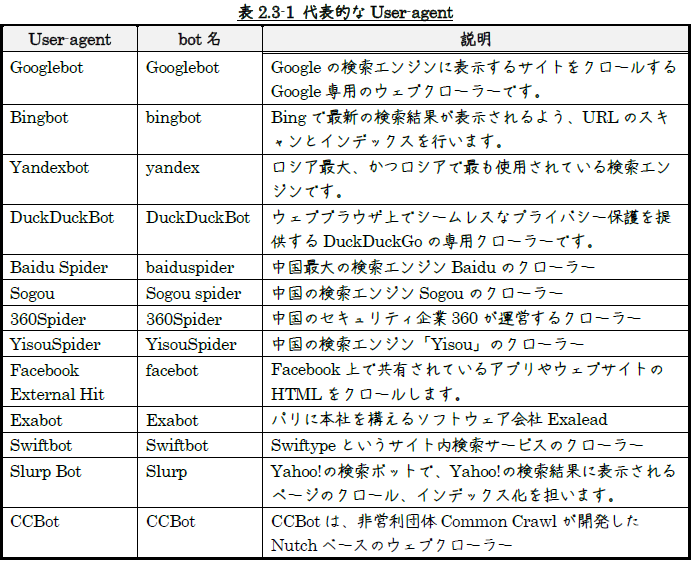
表2.3-1に代表的なUser-agentを示します。
他のUser-agentは、「ユーザーエージェント一覧」、「User-agent 一覧」をキーワードに
検索てみてください。
2025: List of User-Agent strings | DeviceAtlas
Bots and Web Crawlers list | DataDome
なお、User-agentは、使用される文脈によって、botと呼ばれたり、クローラーと 呼ばれたりします。
クローラーの中には、ウイルスやスパム的な動きをするものがあり、
ブロックしたいと思うこともあるかと思います。
例えば、ロシアの検索サイト“Mail.ru”のクローラー“Mail.RU_Bot”があります。
この企業の“Go.mail.ru”というブラウザに感染するウィルスがあるようです。
ブロックしたい場合は、次のように記述します。
|
1 2 |
User-agent: Mail.RU_Bot Disallow: / |
“.htaccess”でもブロックすることができます。
|
1 2 3 4 |
SetEnvIf User-Agent “”Mail.RU_Bot” denybot order allow,deny allow from all deny from env=denybot |
特定の国からのアクセスをブロックしたい場合もあります。
特定の国製のUser-agent、たとえば中国すれば、
少々面倒になりますが、「ユーザーエージェント 一覧 中国」検索結果を元に、
さらに検索を重ねることで中国製のUser-agentを洗い出すことできます。
先程の例と同様に、中国からのアクセスをブロックすることができます。
3 robots.txtのテストツール
robots.txtの記述内容をテストするためのツールがいくつか提供されています。
これらのツールを利用することで、
記述ミスや意図しないクロール制限を事前に発見することができます。
- Google Search Console
-
Google Search Consoleには、robots.txtテスターが搭載されていました。
2025年12月に見たら、無くなっていました。
ただし、Googlebotがrobots.txtの内容をどのように実行したのかを
確認することができます。
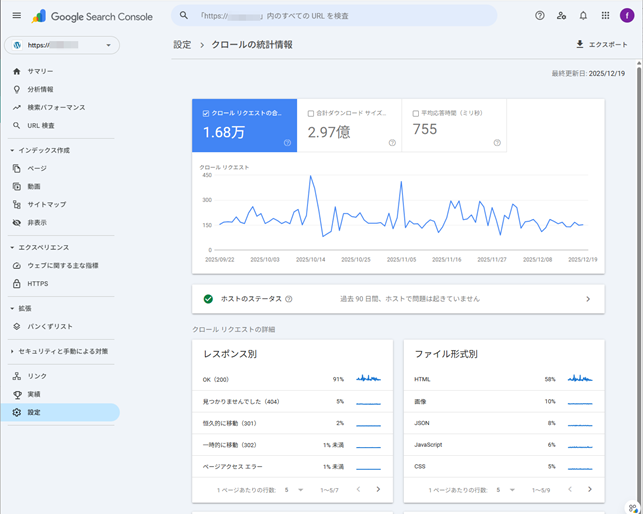
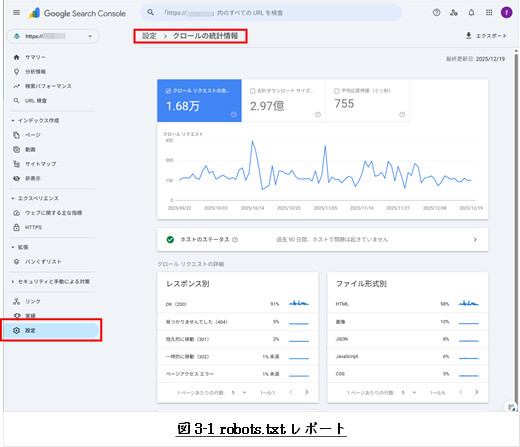
robots.txtレポートには、サイトの上位20個のホストに対してGoogleが検出した
robots.txtファイル、前回のクロール日、発生した警告やエラーが表示されます。
また、急いでいる場合には、
レポートからrobots.txtファイルの再クロールをリクエストすることもできます。
- robots.txt Checker
-
オンラインで利用できるrobots.txtチェッカーツールは、
robots.txtの構文エラーや潜在的な問題を検出できます。
robots.txtチェッカーツールは、“robots.txt checker”で検索すればいくつか見つかります。
下に見つかったものいくつか挙げておきます。
robots.txt Validator and Testing Tool | technicalseo.com
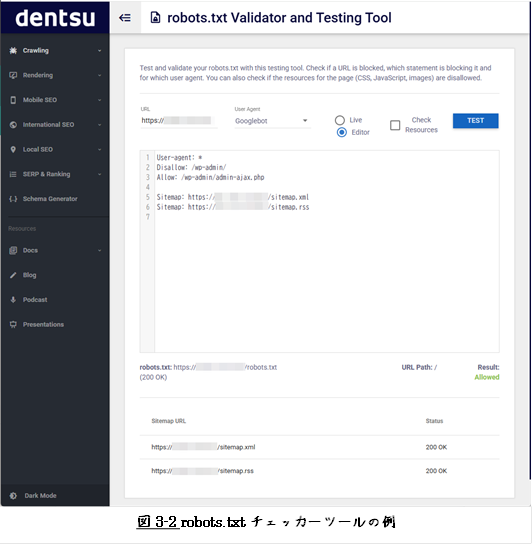
下に、robots.txtチェッカーツールの一例を示します。
robots.txtテスター│完全無料でrobots.txtを確認 | WEBSITE PLANET
Robots.txt チェックツール | SEO FREE
以上
本記事の元となっているWordで作成したPDFを
ページ最後に貼り付けました。
少しでも役に立てていただければ、うれしく思います。
このPDFファイルは、自由に配布されてもかまいません。
ただし、再配布の際には、
入手元と著者名は明らかにしてください。
なお、上のPDFファイルの内容、また本文中の記述に、
誤字や脱字、誤った内容の記述など見つかりましたら、
下に示すフォームでご連絡いただければ幸いです。

コメント